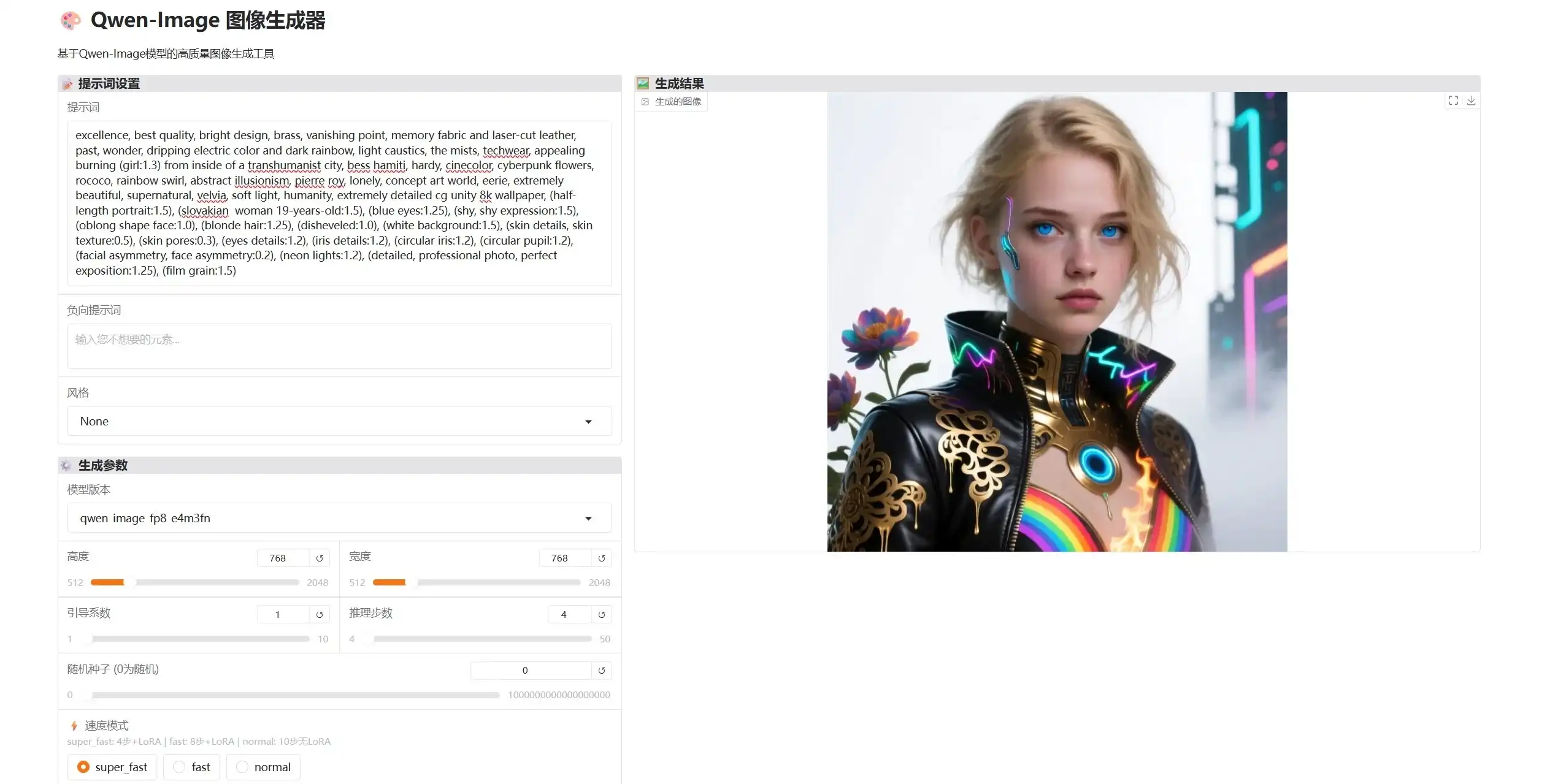
国产AI画画太强了!一句话生成高清美图,支持中文提示词,最低6G英伟达即可运行,15秒出图 Qwen-Image+Edit一键整合包 v20250828 新增 qwen-image-edit-2509-lightningv2.0-20250927 整合包Qwen-Image 是由通义实验室研发、集成于
Qwen(通义千问) 系列的多模态
大模型,核心定位是突破纯语言模型的能力边界,通过在 Qwen 成熟的语言理解基础上深度融合视觉处理模块,实现 “文本 + 图像” 跨模态信息的协同处理与智能交互,为各类需要图文联动的场景提供高效、精准的 AI 支撑。
模型具备精细化图像内容解析能力,不仅能识别图像中的物体、场景与细节,还可基于视觉信息进行逻辑推理(如判断物体关系、场景上下文)与细粒度语义分析(如区分相似物体特征、解读图像隐含信息),结合文本输入生成连贯、准确的自然语言描述,适配从日常场景到专业领域的多样化图文理解需求。
采用 “视觉编码器 + 大语言模型” 深度融合的统一架构,无需依赖多模块拆分协作,可直接完成从 “图像像素信号” 到 “语义级理解与生成” 的端到端处理。这种设计既减少了跨模块数据损耗,又提升了模型对开放域视觉语言任务的适配性,避免了传统多模态方案中 “流程割裂” 的问题。
支持一站式解决多种跨模态任务,无需额外开发适配,核心覆盖:
- 生成类任务:图像描述(为图像自动生成自然语言文案);
- 交互类任务:视觉问答(VQA,基于图像内容回答文本问题);
- 匹配类任务:图文匹配(判断文本与图像的相关性)、图文检索(根据文本找对应图像 / 根据图像找对应文本);
- 分析类任务:图像分类(对图像内容进行类别标注)、文档理解(解析文档图像中的文字、表格、图表信息)。
继承 Qwen 大语言模型的优势,在处理 “需深度理解 + 推理” 的复杂任务时(如 “根据图像分析事件因果”“解读图表数据并生成结论”),既能保证生成内容的流畅性与准确性,又能体现清晰的逻辑链条,避免 “视觉信息误读” 或 “回答与图像脱节” 的问题。
模型训练基于大规模、多样化的图文对数据集,覆盖日常生活、工业场景、学术研究、艺术创作等多领域图像类型,以及不同风格、不同语言的文本描述,确保在面对非训练集内的新场景、新内容时,仍能保持稳定的理解与生成效果,降低实际应用中的 “场景适配门槛”。
Qwen-Image 凭借跨模态能力,可作为核心组件嵌入多领域应用,典型场景包括:
- 智能交互领域:智能客服(结合产品图像解答用户疑问)、无障碍阅读(为视障用户描述图像内容);
- 内容创作领域:辅助创作(为设计图 / 摄影作品生成文案、根据文本描述匹配参考图像)、自动化报告生成(解析数据图表并生成文字报告);
- 教育与办公领域:教育辅导(通过图像讲解知识点,如解析实验图像、文物图像)、文档数字化(自动提取合同、表单等文档图像中的关键信息);
- 内容审核领域:图像内容审核(结合文本标签判断图像是否合规,提升审核精准度)。
Qwen-Image 是通义千问系列在多模态方向的重要突破,标志着该系列从 “纯语言智能” 向 “具身化感知与理解” 的演进 —— 通过引入视觉感知能力,让 AI 更贴近人类 “看 + 读 + 想” 的认知模式,为下一代多模态人工智能应用(如智能机器人、AR/VR 交互、智能座舱)的研发奠定核心基础。
整合包说明
1 支持50系显卡,最低英伟达6G显卡就可以运行,我的4070tis 可以15秒出图
2 安装好你显卡能支持的最高cuda版本即可
3 Qwen-Image 模型很强大的,会继续开发的。
4 暂未修改任何代码。
20250829更新记录
1添加Qwen-Image-Edit
20250924更新记录
1 新增了一个整合包Qwen-Image-Edit-2509
2 说实话 效果很是一般,有想尝鲜的小伙伴 可以试试。
Qwen-Image、通义千问、多模态
大模型、图文理解与生成、视觉问答 (VQA)、端到端建模、跨模态任务、图文匹配