InfiniteTalk 是由 MeiGen-AI 团队开发的突破性
开源项目,聚焦长视频生成领域的核心痛点 —— 打破传统数字人技术的时长限制,通过创新的稀疏帧技术与优化的深度学习架构,实现
任意长度、自然流畅的会说话视频生成(支持数小时级连续输出)。项目兼容多模态输入,可精准同步表情与动作,同时具备高
内存效率,为虚拟主播、教育内容创作、多语言本地化等场景提供高效解决方案,且完全
开源,为开发者与研究者提供灵活的技术工具。
- 突破性技术:攻克传统 TTS(文本转语音)与数字人视频生成的 “5-10 秒片段限制”,支持生成数小时甚至更长的连贯会说话视频,满足长时内容创作需求。
- 连续生成稳定性:通过时序一致性模块保障长视频中动作、表情的连贯性,避免片段割裂感。
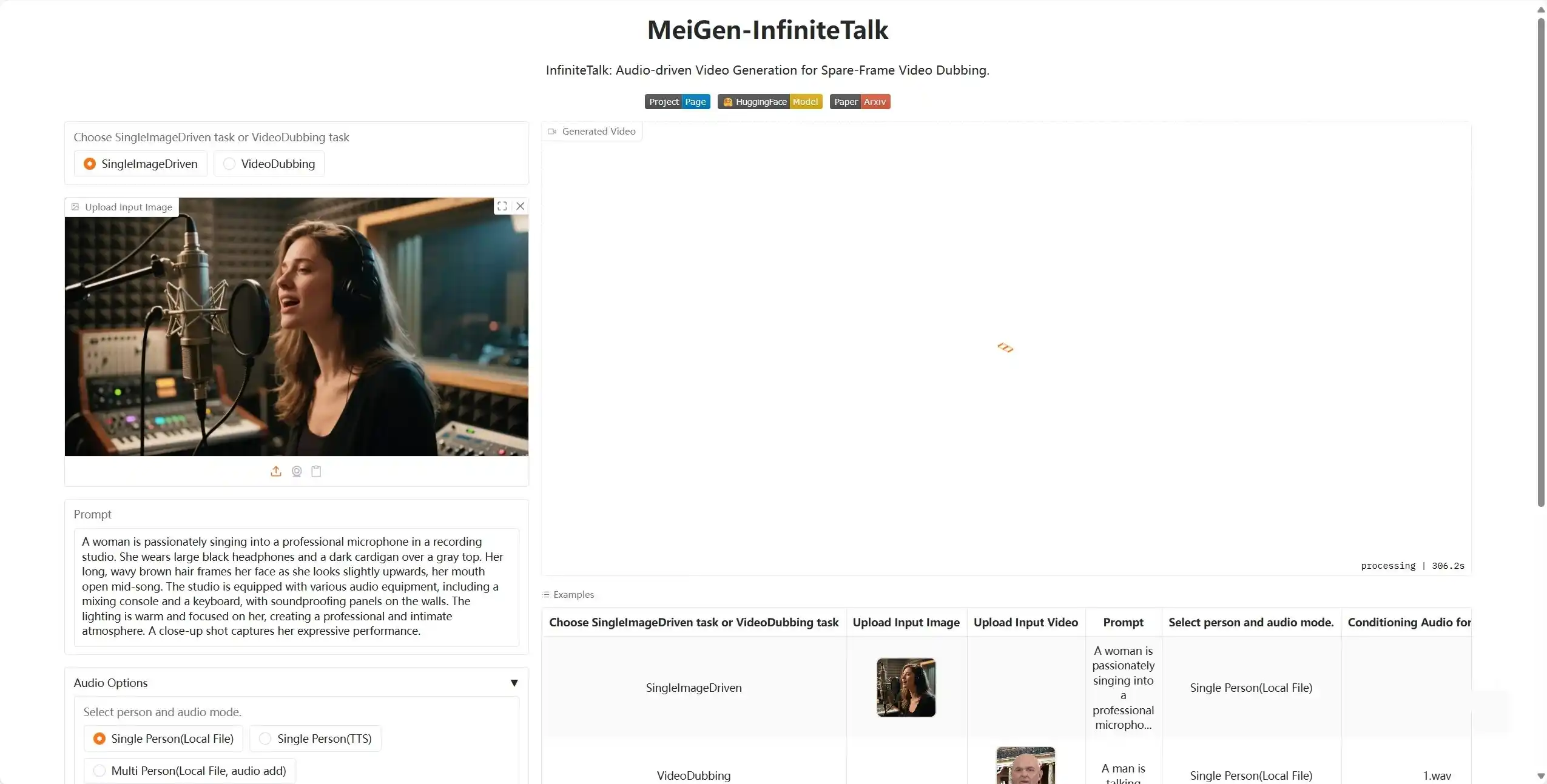
支持三种核心输入模式,覆盖不同使用场景:
- 低复杂度处理:采用 “稀疏帧视频配音技术”,通过关键帧选择策略大幅降低长视频生成的计算量,提升运行效率。
- 内存瓶颈突破:针对长视频生成的内存压力优化,在保障画质的同时,降低硬件资源占用,为无限长度生成提供技术支撑。
- 精准唇形同步:深度解析音频特征,生成与语音节奏、发音细节完全匹配的口型动作。
- 自然头部运动:基于语音韵律智能生成轻微头部摆动、点头等动作,避免 “僵硬静态”。
- 全身动作协调:区别于多数仅支持面部的数字人技术,可同步生成上半身自然动作,提升视觉真实感。
InfiniteTalk 基于深度学习框架构建,核心技术组件分工明确,保障整体性能:
- 音频特征提取模块:从输入音频中提取语音特征(如音调、节奏)与韵律信息,为动作同步提供数据基础。
- 稀疏帧生成器:项目核心创新点,通过关键帧筛选与插值计算,在降低计算复杂度的同时,保障视频流畅度。
- 时序一致性模块:监控长视频中帧与帧之间的动作、表情衔接,避免出现 “跳帧”“动作断裂” 等问题。
- 多模态融合网络:将音频特征与视觉特征(图像 / 视频画面)深度融合,确保口型、动作与声音的精准匹配。
- 虚拟主播领域:创建 24/7 不间断运行的虚拟主播,用于直播、新闻播报、品牌代言等。
- 教育内容创作:自动生成长篇教学视频(如课程讲解、知识科普),降低内容制作成本。
- 有声读物可视化:将音频版有声读物转化为 “人物出镜讲解” 的视频,提升内容吸引力。
- 多语言内容本地化:快速为视频替换不同语种音频并同步口型,实现多地区内容适配。
- 无障碍服务:为听障人士提供 “声音可视化” 视频,通过口型与动作辅助理解内容。
- 硬件要求:支持英伟达 50 系显卡,最低需 16G 显存 + 48G 内存(确保长视频生成的硬件支撑)。
- 代码完整性:整合包未修改任何原始代码,保持项目原生功能与稳定性。
- 下载方式:仅提供迅雷下载(因压缩包体积过大,其他网盘暂不支持上传)。